
You will hear "context” from every AI SOC vendor. Here's a five-question rubric to tell which ones actually have it, before you write the check.
After sitting in close to a hundred AI SOC deal rooms over the last year, I can tell you the word "context" came up in every single one, and it meant something different every time.
We just came back from the Gartner Cybersecurity and Risk Summit. At SecOps village it seemed like every booth had the same 2 words on it - AI SOC. And every keynote talked about context.
Earlier at RSAC: Microsoft, CrowdStrike, Google, Cisco, Arctic Wolf, every major platform vendor pushed an AI SOC announcement in the same five days, and industry coverage put agentic AI security at the center of the conference. Same claim: our agents understand your context.
The problem is that when you put six vendors in a buyer's spreadsheet, the word "context" means six different things, and almost nobody on the buyer's side has noticed.
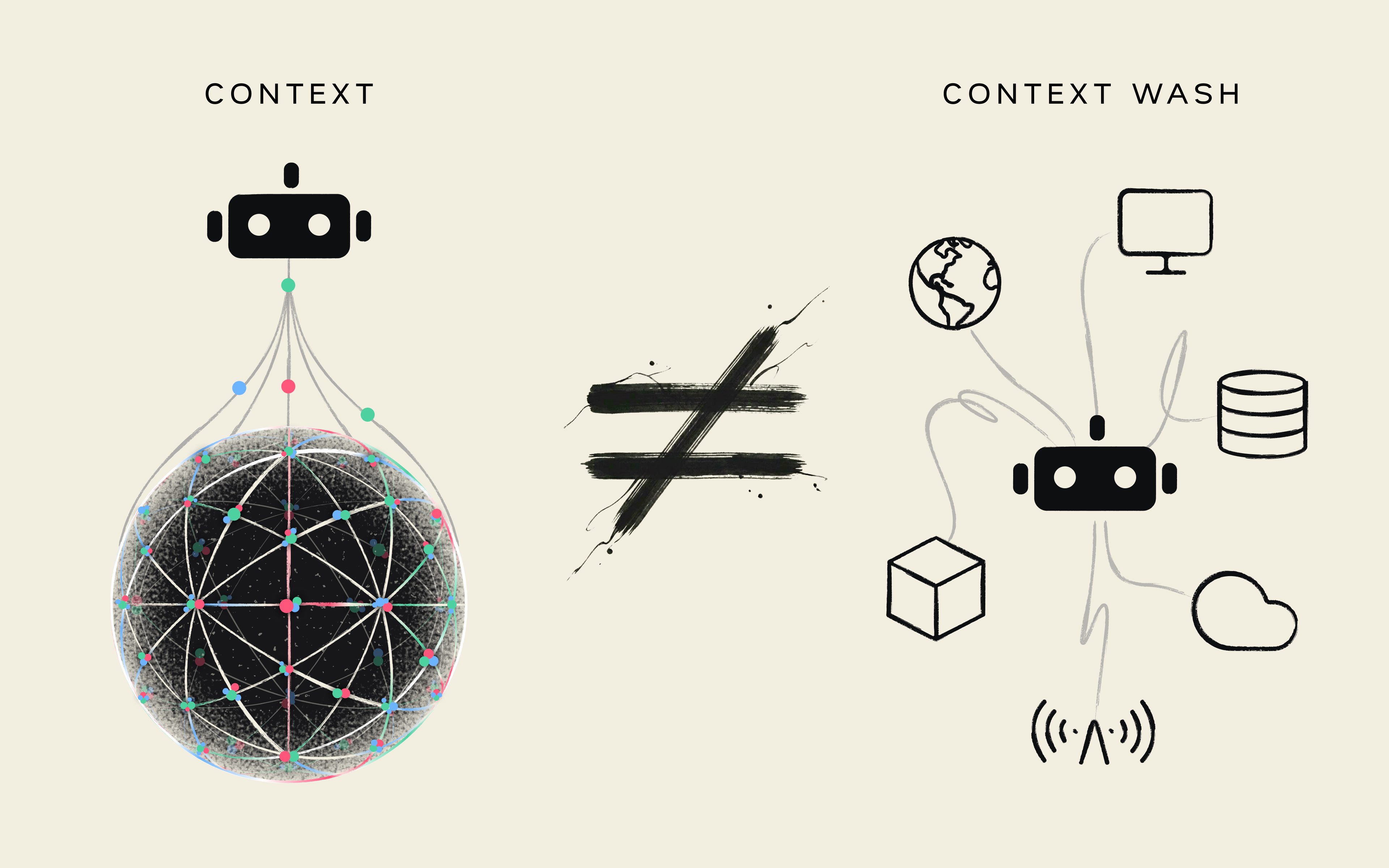
Context is Officially Out of Context
I call this context wash: the term gets slapped onto a product that hasn't been structured to deserve it. The label changes. The substrate doesn't.
In a single hour at the Gartner Summit I heard "context" used to describe a SIEM query, a session-history thread, a policy-weighted alert score, a UI-aware copilot, and an analyst-typed prompt. Same word. Five products. Five entirely different things. Buyers nodded along, because the word sounds like the same thing.
It isn't. Most AI SOC products today don't maintain context. They retrieve data, and hope to generate context in real time. And there’s a huge difference. Retrieving data and generating context on the fly means the agent meets your environment fresh every time. It's an analyst on their first day, again and again, with no memory of what they learned yesterday.
What Context Wash Actually Looks Like
Here are the five flavors I see in the wild. None of them are bad on their own. All of them are dishonestly named.
- Context as retrieval. "Our agent pulls from your SIEM at investigation time." That's a SQL query with a chatbot in front of it. The agent is fetching data the moment it needs an answer, not reasoning about an environment it already understands.
- Context as session memory. "It learns from analyst feedback over time." Useful, but that is this specific analyst’s context. The agent looks through a straw at what this specific analyst did, or told it in this specific conversation. It does not have an organizational model of how your company actually works. And the context is as good as the analyst is. For example: a junior analyst’s notes teach the agent to auto-close failed logins from one service account, but they never captured that the same pattern is critical for the payroll system, so the agent inherits the blind spot instead of the organization’s actual risk model.
- Context as policy weighting. "It factors in asset importance and risk tolerance." That's a scoring rubric. Risk-weighted scoring is table stakes for any modern triage tool; calling it context is a marketing move.
- Context as page awareness. "Copilot understands what page you're on and grounds its answers in the signals visible there." That's a useful UI feature. It is not the same thing as understanding your environment.
- Context as user-injected prompt. "You can inject context to guide the investigation." Read that one carefully. The buyer just paid for an AI agent that requires the analyst to bring the context. That's the customer doing the work, with a model as a typing assistant.
- Context as aggregation. “We pull context from dozens of sources.” Collecting signals from everywhere is not the same as structuring them. Tools that aggregate without building a context structure burn time and tokens re-reading raw data on every query, and the gaps between disconnected sources are exactly where hallucinations creep in.
- Context as acquisition. “We acquired a company to give us context.” Context bolted on through an acquisition is someone else’s structure stapled to your stack. It rarely understands your environment the way natively, home-grown context does, and the seams show up precisely when an investigation crosses the boundary between the two systems.
The cleanest test I've found is the substitution drill. Instead of: "Pulling the asset criticality score from your CMDB." What real context says: "This server is owned by the FedRAMP team, the on-call rotation is in the #fedramp-oncall Slack channel, the last config change was Priya's Terraform PR #4128 approved by James, and the thread approving that change is in #infra-changes from three days ago."
The first one is a row in a database. The second one is what a senior analyst on your team actually knows.
Why This Gap Is About to Get Expensive
Marketing-vs-reality gaps don't show up at signing. They show up six months in, when the AI is wrong, the analyst can't tell why, and the SOC has nothing to fall back on. Help Net Security has been hammering this point for most of 2026: vendor claims and production reality are not converging.
The places it bites in production are the ones every senior analyst will recognize. The agent closes a case and can't explain why it closed it - your auditor is going to have a problem with that. The agent flags John on the SRE team logging in from Tokyo as anomalous, because nobody told it John flies to Tokyo every Tuesday, your senior analyst spends the next twenty minutes manually rebuilding context that should have been there. The agent has no opinion on whether the engineer who pushed the IaC (infrastructure-as-code) change was authorized to do it - so the service-account masking problem, the one that's been chewing through SOC hours for a decade, stays exactly as unsolved as it was before you bought the AI.
By the time the buyer figures out which definition they bought, they've already trained their analysts to trust it. That's the expensive part. Trust in a tool you can't audit is worse than no tool at all. And a tool never earns that trust on its own. Analysts are smart people, and what really happened is that you trained your team to trust it, one verifiable, well-reasoned decision at a time. Strip out the reasoning they can check, and that trust never forms.
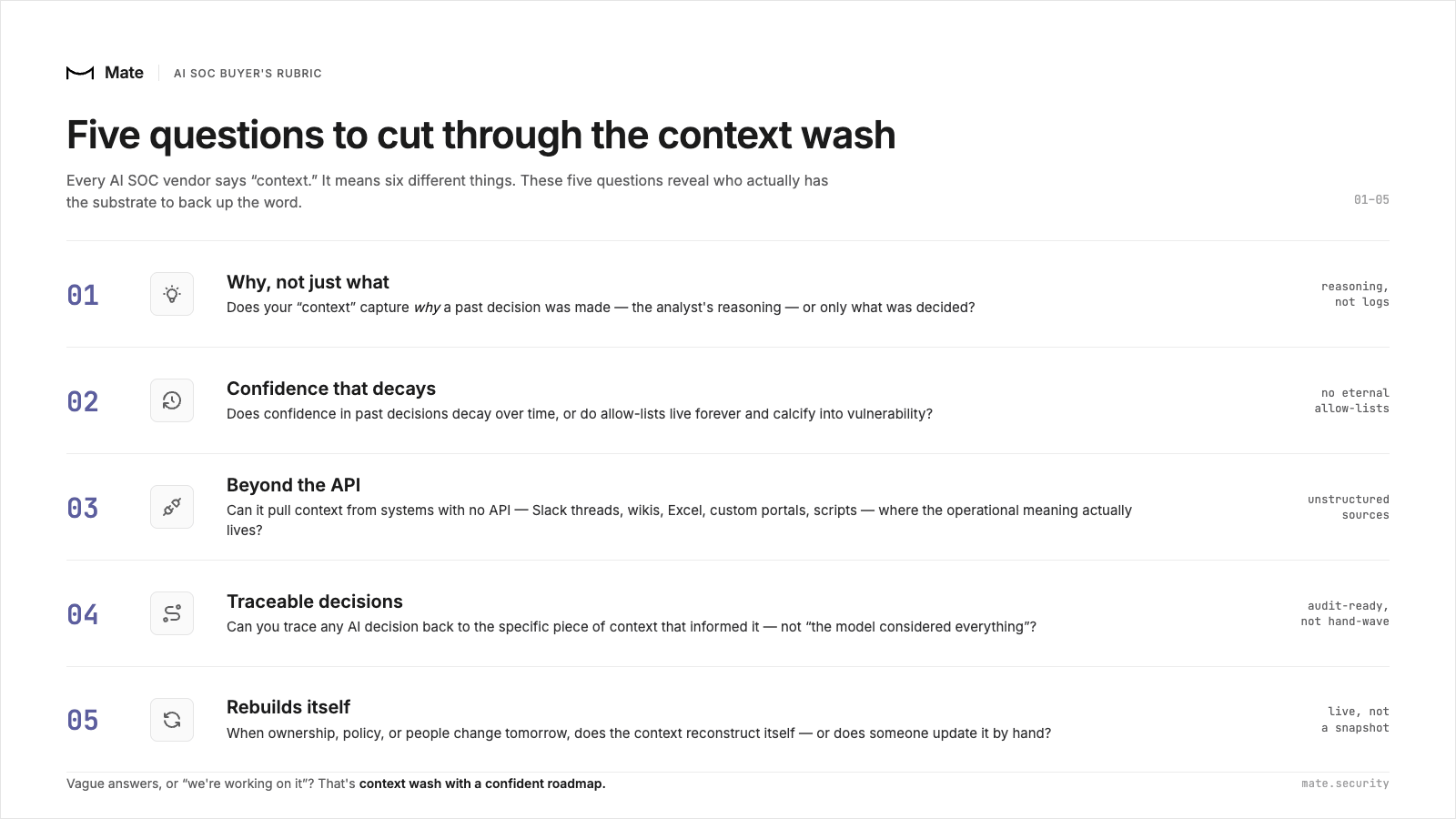
Five Questions to Cut Through the Context Wash
This is the rubric I now hand every buyer I work with. None of these questions are about Mate. They're about whether any vendor, including us, has the substrate to back up the word.
- Does your "context" capture why a past decision was made, or only what? Listen for whether the vendor describes capturing analyst reasoning, not just decision logging. If a senior analyst leaves tomorrow, their judgment either lives in the system or it doesn't.
- Does confidence in past decisions decay over time, or do allow-lists live forever? Static allow-lists are technical debt that calcifies into vulnerability — a pattern Oren has written about extensively. A decision made eighteen months ago by an analyst who has since left should not have the same weight as a decision made yesterday.
- Can it pull context from systems without an API, Slack threads, wikis, Excel, custom portals, scripts? Most production SOC context lives outside the structured tools. Vendors that only speak SIEM/EDR/IdP miss the half of your environment that actually carries the operational meaning.
- Can you trace any AI decision back to the specific piece of context that informed it? If the answer is "the model considered everything," that's not transparency, that's a hand-wave. Auditors will not accept "the model considered everything." Neither should you.
- When ownership, policy, or people change tomorrow, does the context reconstruct itself, or does someone have to update it manually? A graph that doesn't rebuild dynamically is a snapshot, not context. Snapshots get stale within weeks of any real organizational change. Make the vendor get specific: what is the context building block, and what is the context structure built from it? What are the sources it draws on, and how is it kept fresh as the environment changes? And can they actually show you, live, how that context is maintained, not just describe it on a slide?
If a vendor's answers to those five questions are vague, hand-wavy, or "we're working on it", and can’t even show it in the product demo, you don't have a context-aware product. You have context wash with a confident roadmap.
What “Real” Context Requires
First, a definition. “Real” context is better called reasoning-driven context: its building block is memory, captured pieces of reasoning about why things are the way they are, not raw data retrieved on demand. It is exactly what a senior analyst carries in their head. Structured together, those memories form a security context graph: a living model of your environment that the AI reasons over. We built Mate around the premise that those five questions had to be answerable on day one. The architectural pieces that need to be in place include reason mining, memories, confidence decay, dynamic reconstruction and most importantly. Our Chief Product Officer walks through what context actually requires under the hood in more depth.
The result of building context in a structured way is, first and foremost, trust. When agents reason against a context structure as the foundation, AI starts reasoning like an experienced analyst, hallucinations stop, and AI onboarding accelerates to a day or less. But today the same vendors who oversold "autonomous SOCs" eighteen months ago are now overselling context.
Context isn't a feature you can slap-on on after the fact. It's a foundation you either built, or you didn't. Don't pay for the wash.




