- Detection engineering improves threat detection quality: It applies testing, version control, and continuous tuning to reduce false positives and help SOC analysts focus on real threats.
- Effective programs combine multiple detection methods: Rule-based, behavior-based, threat intelligence-driven, and analytics-driven detections work together to improve coverage and identify complex attacks.
- Detection engineering is a continuous process: Teams collect telemetry, map threats, validate detections, and tune rules over time to keep pace with evolving environments and attacker behavior.
- Context and enrichment are critical for accurate investigations: High-fidelity detections depend on telemetry, organizational context, and workflows that connect alerts to meaningful business and security insights.
What Is Detection Engineering?
Detection engineering is the discipline of designing, testing, and maintaining the logic security teams use to identify malicious activity across their environments. It applies software engineering principles such as version control, testing, and continuous improvement to the development of detection rules and workflows. The goal is to surface real threats reliably while reducing false positives and alert fatigue for SOC analysts.
Why Detection Engineering Matters for SOC Teams
SOC teams operate under constant pressure: too many alerts, too few analysts, and adversaries who continuously adapt their techniques to blend into normal activity. Detection engineering provides security operations with a structured way to fight back by turning ad hoc rule writing into a repeatable, scalable practice that evolves with the threat landscape.
- Managing High Alert Volumes Without Overwhelming Analysts: Modern environments generate millions of events daily, and untuned detections can flood SOC queues with low-value alerts. Detection engineering reduces that noise by building precise detections that account for factors like identity behavior, asset criticality, and attack patterns. This helps analysts focus on signals that genuinely require investigation instead of wasting time on repetitive false positives.
- Improving Detection Coverage Across Environments: Attackers move laterally across endpoints, identities, SaaS applications, and cloud workloads. Mature detection programs reduce blind spots by mapping coverage to frameworks like MITRE ATT&CK, ensuring detections align with the tactics, techniques, and procedures most relevant to the organization instead of relying solely on default vendor rules.
- Enabling Faster Investigation and Response: Well-engineered detections provide analysts with the context needed to triage incidents quickly, including what triggered the alert, why it matters, and what systems or identities may be affected. This shortens mean time to detect and mean time to respond, two metrics directly tied to breach impact and attacker dwell time.
- Supporting Scalable Security Operations: As organizations grow, manually tuning detections one rule at a time becomes unsustainable. Detection engineering applies engineering discipline to detection work so SOC operations can scale without being limited by analyst headcount alone.
Types of Detection Engineering Approaches
Detection engineering is not a single technique but a collection of approaches that work best in combination. Each method has strengths and limitations, and mature SOC teams typically blend several approaches to improve detection fidelity across different attack scenarios.
Rule-Based Detection Methods
Rule-based detection forms the foundation of most SOC programs. It uses predefined logic such as signatures, thresholds, and pattern matching to flag activity that meets specific criteria. Examples include alerts for repeated failed login attempts, known malicious file hashes, or suspicious command-line arguments. Rule-based detections are highly precise and easy to interpret, but they only identify activity they are explicitly written to detect, making them less effective against novel or rapidly evolving attacks.
Behavior-Based Detection Models
Behavior-based detection focuses on how users, systems, and applications normally operate rather than relying solely on static indicators. By establishing behavioral baselines, these models can identify anomalies such as a service account suddenly accessing sensitive data or a workstation communicating with unusual external destinations. This approach is often more resilient against attacker evasion because behaviors are harder to disguise than tools or infrastructure, a principle reflected in David Bianco's Pyramid of Pain. The trade-off is that behavioral detections require strong baselines, contextual enrichment, and continuous tuning to avoid excessive noise.
Threat Intelligence-Driven Detection
Threat intelligence-driven detection uses internal and external intelligence sources to guide what detections are built and prioritized. This may include indicators of compromise from active campaigns, attacker TTPs, or intelligence tied to threats targeting a specific industry or geography. When integrated effectively, threat intelligence transforms detection engineering from a generic monitoring exercise into a focused effort aligned with the adversaries and attack paths most relevant to the organization.
Hybrid and Analytics-Driven Detection
Modern detection programs increasingly combine rules, behavioral models, and analytics into hybrid detection strategies. Statistical analysis, machine learning, and cross-platform correlation help SOC teams identify multi-stage attacks that no single detection rule would catch independently. These approaches are particularly effective against low-and-slow attacks, lateral movement, and identity-based threats where individual events may appear benign in isolation but reveal malicious intent when analyzed together. For example, a single login anomaly may not trigger concern on its own, but when correlated with privilege-escalation activity and unusual data access patterns, it may indicate account compromise.
The Detection Engineering Lifecycle
Detection engineering is not a one-time build; it's a continuous lifecycle. Each stage feeds the next, and the program improves with every iteration as new threats emerge and environments change.
- Collect and Normalize Security Data: Effective detection starts with the right telemetry. Logs from endpoints, identity providers, SaaS apps, network traffic, and cloud workloads must be collected, parsed, and normalized into a consistent schema so detections can run reliably across data sources.
- Define Threat Models and Use Cases: Before writing any rule, teams identify which threats matter most to the organization. This involves mapping relevant attacker TTPs, often using MITRE ATT&CK, and translating them into specific detection use cases tied to business risk.
- Build and Validate Detection Logic: Detections are written, tested against historical data, and validated through purple team exercises or breach and attack simulation. Validation confirms the rule fires on real malicious activity and stays quiet on benign noise before it ever reaches production.
- Deploy, Monitor, and Continuously Tune: Once live, detections are monitored for performance: false positive rates, alert volume, and analyst feedback. Rules that drift, decay, or become obsolete are tuned, retired, or rewritten, keeping the detection library aligned with the current threat landscape.
Core Components and Architecture of Detection Engineering
A mature detection engineering program is built on a layered architecture where each component plays a distinct role. Understanding how these layers fit together helps SOC teams design programs that scale and produce high-fidelity alerts instead of overwhelming analysts.
Data Sources, Telemetry, and SIEM/EDR Integration
Detection starts with visibility. Telemetry from endpoints, identity providers, SaaS platforms, cloud workloads, and network sensors converges in SIEM and EDR platforms where it can be searched and correlated. The depth and quality of this data determine what is detectable in the first place, since gaps in logging translate directly into blind spots that no detection rule can compensate for.
Detection Rules, Logic, and Pipelines
This is where raw telemetry becomes actionable. Detection logic, expressed as Sigma rules, KQL queries, YARA signatures, or behavioral models, defines what counts as suspicious. Modern programs run these detections through pipelines that test, version, and deploy logic in a structured way, ensuring rules are peer-reviewed before reaching production and continuously evaluated against new data.
Centralized Context and Enrichment Layers
A detection without context is just an alert. Enrichment layers add the organizational knowledge that makes alerts meaningful: who owns the affected asset, what role the user holds, whether the activity aligns with normal business processes, and how the event relates to recent changes or active investigations. This layer is what turns a generic anomaly into a triageable signal.
Alerting, Orchestration, and Response Workflows
Once a detection fires, alerting and orchestration determine what happens next. Alerts are routed based on severity and ownership, enriched with context, and passed into investigation or response workflows where SOAR platforms, ticketing systems, and case management tools coordinate the human and automated steps that move an alert from detection to resolution.
Common Challenges in Detection Engineering
Even mature detection programs run into recurring obstacles. Most stem from the same root causes: too much telemetry, too little context, and not enough engineering capacity to manage it all.
- High False Positive Rates and Alert Fatigue: False positives often stem from generic vendor rules, missing context, or detections written without a clear threat model. When analysts triage hundreds of low-quality alerts every day, real threats become harder to identify, and analyst burnout increases.
- Limited Context Across Disconnected Systems: Identity, endpoint, SaaS, and cloud telemetry frequently live in separate tools that do not share organizational context. Without a unified view, analysts must manually piece together investigations, slowing response times and increasing the likelihood of missed correlations.
- Detection Gaps and Blind Spots: Coverage gaps emerge when logging is incomplete, when new SaaS applications or cloud services are onboarded without corresponding detection content, or when attacker TTPs evolve faster than the detection library. What is not logged or modeled simply is not detectable.
- Continuous Tuning Burden on Security Teams: Detection logic decays over time as environments, user behavior, and attacker techniques evolve. Rules that generated clean signals six months earlier may suddenly produce excessive noise, forcing security teams to spend significant time tuning, suppressing, and rewriting detections.
- Skill Gaps and Staffing Constraints: Detection engineering requires a rare combination of adversary knowledge, query language expertise, and software engineering discipline. Many organizations struggle to hire and retain personnel with the technical depth needed to support both detection development and day-to-day SOC operations.
Best Practices for Detection Engineering
The strongest detection programs share a set of operating principles that turn detection engineering from a reactive task into a disciplined operational practice.
- Build Detections Based on Real Threat Models: Every detection should begin with a clear understanding of the attack behavior it is intended to identify and why that threat matters to the organization. Mapping detections to adversary TTPs helps teams prioritize meaningful coverage tied to real risk instead of accumulating noisy generic rules.
- Continuously Test and Validate Detection Logic: Detections should be tested against historical telemetry, simulated attacks, and purple team exercises before deployment, then validated continuously as environments evolve. Mature teams also use replay testing and automated regression testing to ensure rule updates do not unintentionally break existing detections or introduce excess noise.
- Reduce Noise with Enrichment and Risk-Based Prioritization: Effective detection programs enrich alerts with organizational context and apply suppression logic, correlation, and risk-based prioritization to reduce unnecessary investigations. Factors such as asset criticality, identity role, business hours, and maintenance windows help distinguish genuine threats from benign anomalies that share similar behavioral patterns.
- Treat Detection as Code and Version Control Rules: Detection logic should be stored in Git repositories, reviewed through peer approval workflows, and deployed through CI/CD pipelines. This improves auditability, rollback capabilities, collaboration, and testing consistency across detection programs. Standards like Sigma also improve rule portability across SIEM platforms.
- Maintain Clear Detection Documentation and Ownership: Every detection should include a documented owner, an explanation of the threat behavior it identifies, required telemetry sources, expected alert behavior, and known false positive scenarios. Without proper ownership and documentation, detection libraries decay into orphaned logic that analysts no longer understand, validate, or trust.
Detection Engineering Metrics That Matter
You cannot improve what you do not measure. The right metrics turn detection engineering from a reactive effort into a measurable operational program, helping teams identify gaps, justify investment, and continuously improve detection quality over time. The stakes are real. According to IBM's 2025 Cost of a Data Breach Report, organizations now identify and contain a breach within a mean time of 241 days, the lowest figure in nine years, meaning detection engineering gaps still translate into months of attacker dwell time before containment.
These metrics are most useful when read together. A high MTTD paired with strong MITRE coverage suggests detection logic is firing too late, while a low alert-to-investigation conversion rate alongside a heavy tuning backlog points to a noise problem that engineering capacity is not keeping up with. Reading them in combination is what separates a reactive SOC from a maturing detection engineering program.
Detection Engineering Powered by Automated, Contextual Investigations With Mate Security
Strong detection engineering surfaces the right signals, but signals alone do not resolve incidents. What happens after a detection fires is where many SOC programs struggle. Mate Security closes that gap by pairing detections with automated, contextual investigations that follow organizational SOPs while adapting dynamically to each alert.
- No Alert Left Behind, Contextual Investigation of Every Signal in Seconds: Mate investigates 100% of alerts automatically, including informational and low-severity alerts that traditional SOC workflows often deprioritize. Each investigation is completed in seconds and produces a structured summary containing evidence, reasoning, and a recommended verdict.
- SOPs as Gateways, Investigations That Adapt Dynamically to Context: Mate follows the SOC's defined SOPs and Gamebooks (its adaptive investigation playbooks) while adjusting each investigation based on the alert, affected asset, user role, recent activity, and surrounding events. The result is investigation logic that mirrors how experienced analysts actually work, not rigid sequences that break when conditions change.
- Closing False Positives with Context-Aware Reasoning Instead of Rigid Filters: Rather than relying on suppression rules that risk hiding genuine threats, Mate evaluates alerts against organizational context, historical outcomes, and threat models to determine whether activity represents meaningful risk. Detection libraries remain precise without sacrificing visibility into real threats.
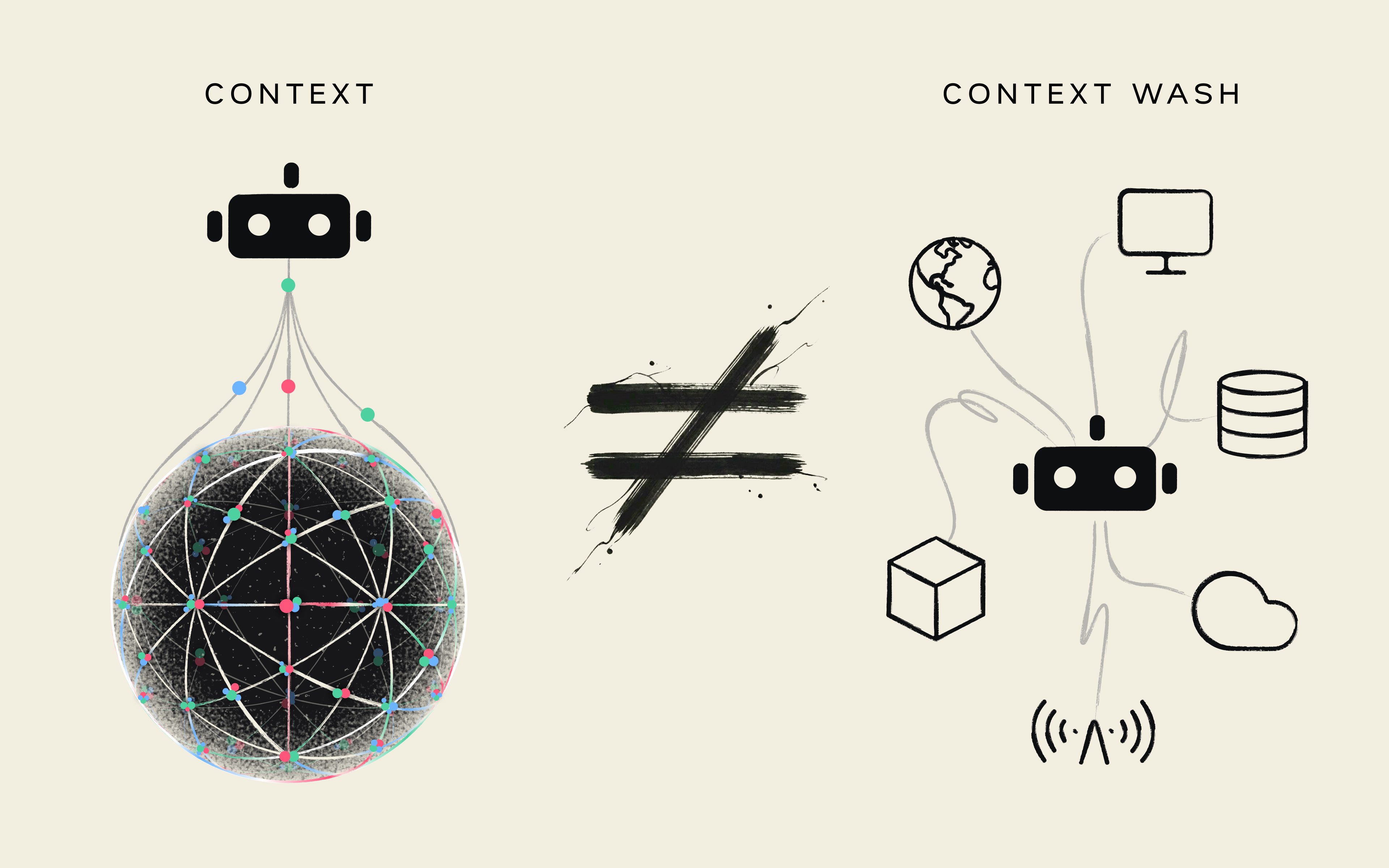
- The Security Context Graph, Organizational Knowledge That Improves Detection Accuracy: At the core of the platform is the Security Context Graph, which continuously captures institutional knowledge across security tools, HR systems, messaging platforms, ticketing systems, and SOPs. This evolving context grounds every investigation in how the organization actually operates.
- 24-Hour Onboarding Without Weeks of Manual Tuning: Mate onboards in one day and starts delivering investigation-ready results. Most AI SOC platforms still require months of training and tuning cycles before they produce reliable verdicts. That difference shortens time to value, lowers the onboarding burden on analysts, and means detection engineering improvements translate into investigative coverage almost immediately.
- Supervised Response That Keeps Analysts in Control: Mate recommends response actions or executes predefined workflows with human approval, preserving analyst oversight for high-impact decisions while removing manual overhead from repetitive investigative tasks.
Conclusion
Detection engineering has become a core part of modern security operations, turning reactive alert handling into a structured discipline that scales with the threat landscape. Strong programs combine the right telemetry, threat-informed detection logic, contextual enrichment, and continuous tuning to surface real threats without burying analysts in noise. But even the best detections only deliver value when investigations match the speed and precision of the alerts themselves.
That is where context-driven AI SOC platforms like Mate Security extend the impact of detection engineering. By grounding every investigation in an organizational context and pairing it with supervised response workflows, Mate helps SOC teams investigate every signal thoroughly while keeping analysts focused on the decisions that actually demand human judgment.
FAQs
Detection engineering creates reusable detection logic for ongoing monitoring, while threat hunting is a hypothesis-driven search for hidden attacker activity.
- Detection engineering operationalizes known attack patterns into scalable monitoring workflows.
- Threat hunting investigates suspicious behaviors that may not yet have formal detections.
- Mature SOCs feed successful hunt findings back into the detection engineering lifecycle.
- Combining both approaches improves long-term detection coverage and reduces attacker dwell time.
Learn more about Swiss cheese security.
High-performing SOCs reduce false positives by enriching detections with organizational context instead of relying solely on static rules.
- Correlate alerts with user identity, asset criticality, maintenance windows, and business workflows.
- Prioritize alerts based on risk scoring rather than triggering investigations on every isolated anomaly.
- Continuously validate detections against historical telemetry and analyst feedback loops.
- Retire or rewrite detections that consistently generate low-value alerts.
MITRE ATT&CK helps SOC teams map detections to real adversary tactics, techniques, and procedures instead of relying on generic monitoring.
- Identify which ATT&CK techniques are most relevant to your organization’s threat model.
- Build detections that align to attacker behaviors across endpoints, identities, cloud, and SaaS systems.
- Measure coverage gaps to identify blind spots attackers could exploit.
- Use ATT&CK mapping to prioritize future detection development and validation exercises.
Discover why Mate built the security context graph.
Mate reduces alert fatigue by applying contextual investigations and adaptive reasoning instead of broad suppression rules.
- Investigate low-severity and informational alerts automatically instead of ignoring them.
- Correlate surrounding events, user behavior, and asset context before assigning verdicts.
- Preserve visibility into suspicious activity while filtering operational noise intelligently.
- Deliver investigation-ready outputs that analysts can review quickly instead of starting from raw telemetry.
Find out the limitations of autonomous SOCs.